#PowerBI: контекст и константы
Разобраться в работе контекста в языке #DAX бывает не просто. Иногда кажется, что вот - уловил уже суть, но вдруг получаешь результат, который не можешь объяснить.
В прошлой статье о контекстах я попытался предложить упрощенный вариант понимания контекста фильтра. В ней я разбирал работу контекста на простом примере, не вдаваясь в подробности и теорию.
Сегодня же, хочу заглянуть чуть глубже и на примере одной визуализации рассказать о том, что может влиять на формирование контекста вычисления, какие функции используются для формирования визуального элемента и как на это могут повлиять константы, связи и наполнение визуальных элементов.
За основу возьмём всю ту же модель данных:
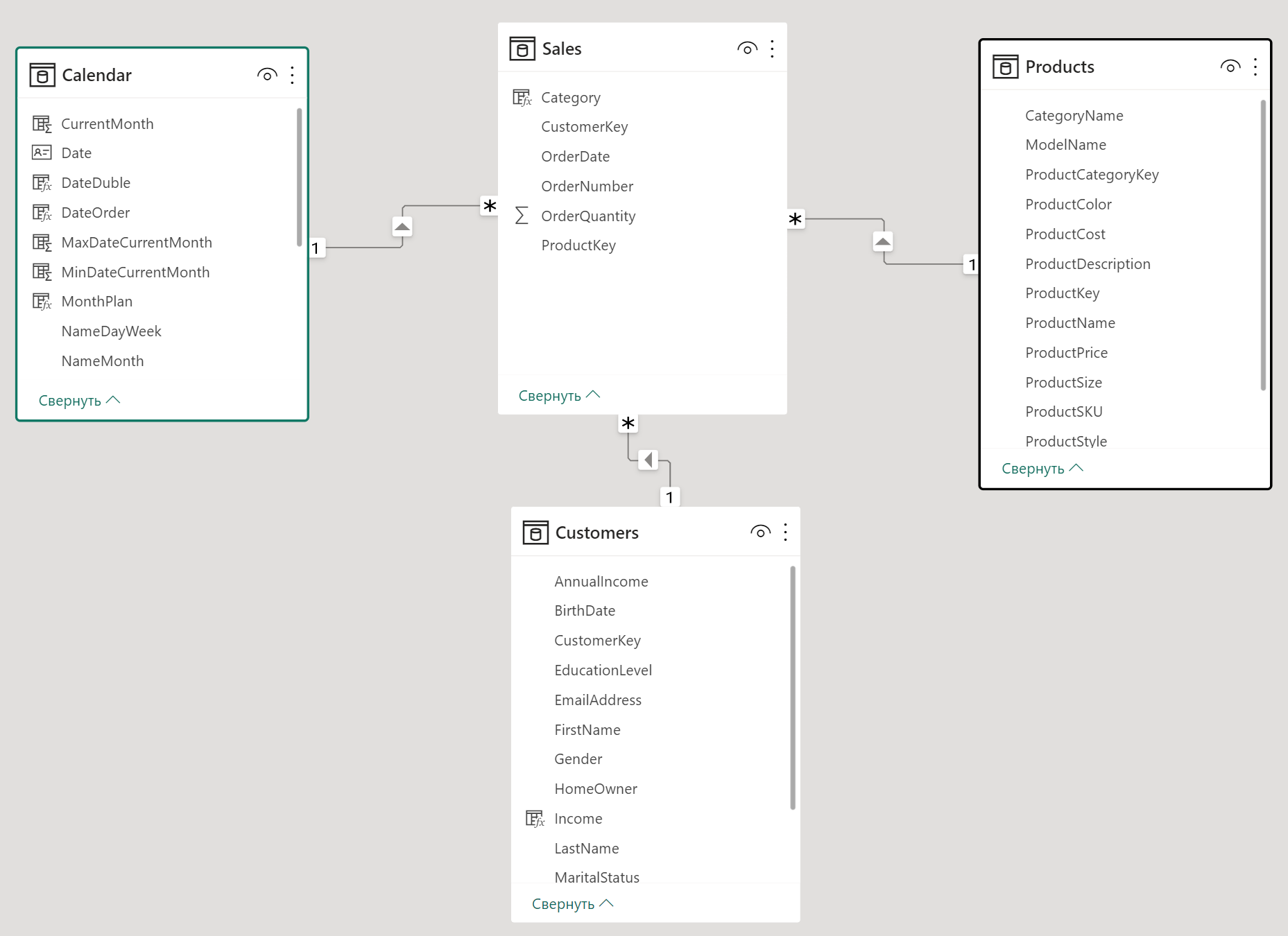
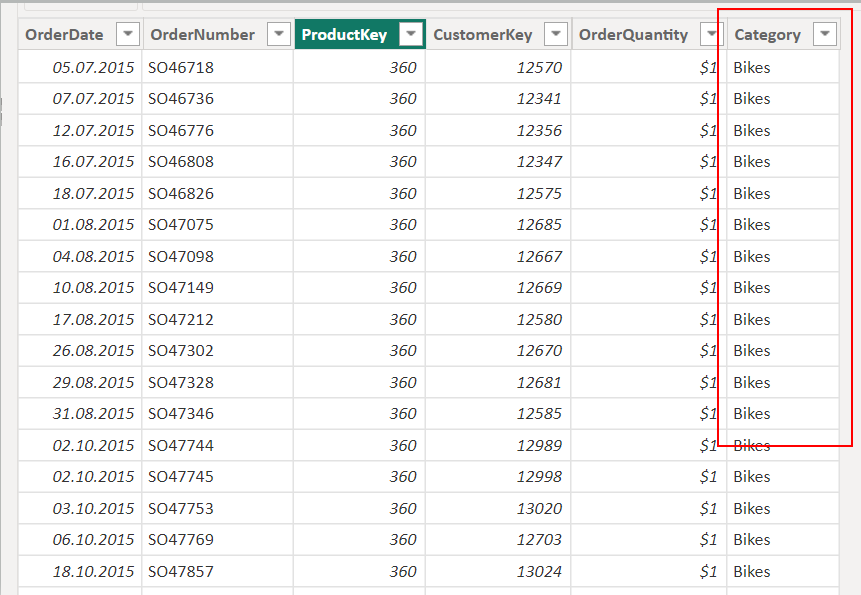
Единственное, по какой-то причине в таблице фактов добавлен столбец Category, который соответственно содержит названия категорий товаров:
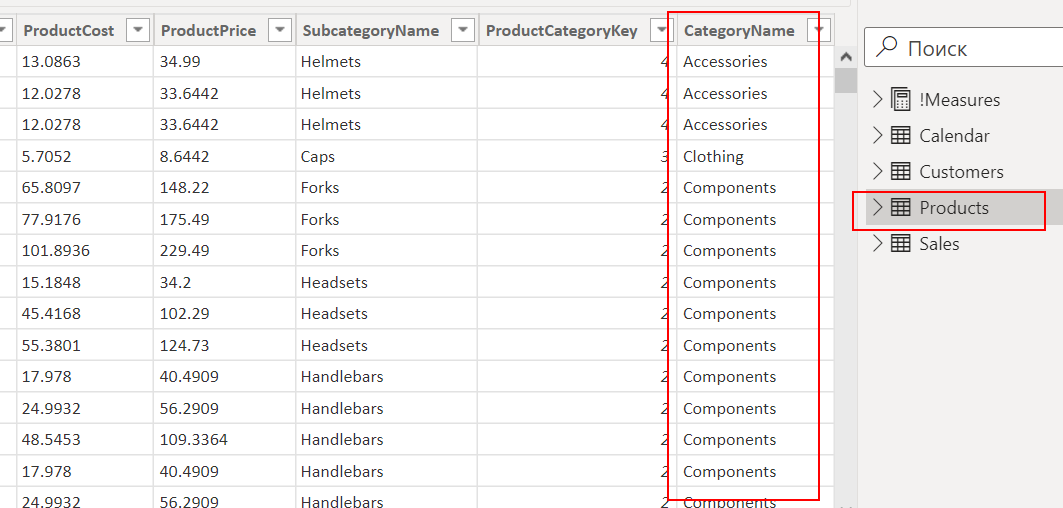
Хотя у нас есть информация о категориях товаров в связанной таблице Products:
Также в модели создана мера, которая считает количество единиц проданного товара:

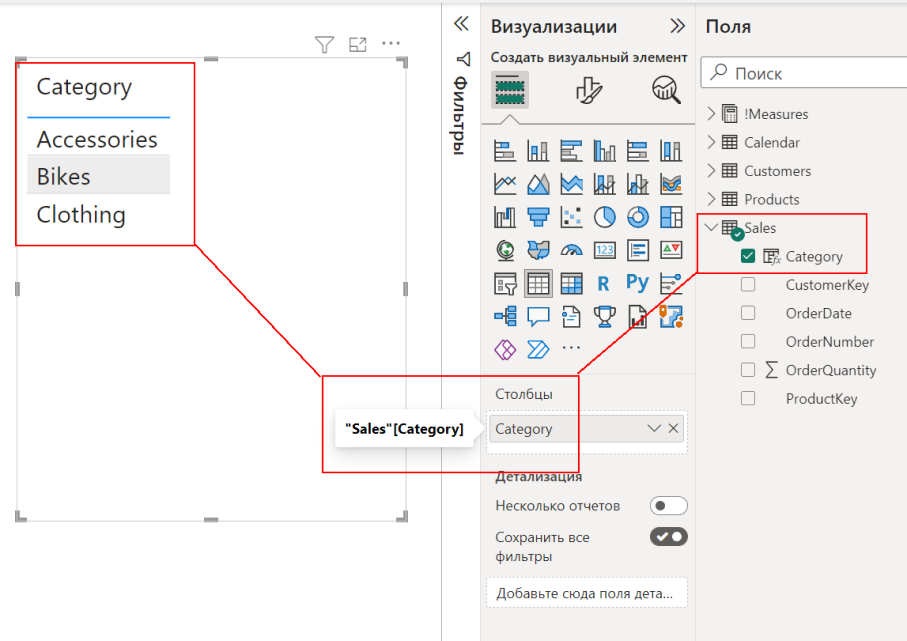
На листе отчёта создадим визуальный элемент Таблица и добавим в него столбец Category из таблицы Sales:
Для того, чтобы отобразить визуальный элемент, движку PowerBI необходимо вычислить таблицу, которая получается в результате группировки. Чтобы посмотреть как это происходит, воспользуемся функционалом анализатора производительности (вкладка "Представление" - "Анализатор производительности" - "Таблица" - "Запрос DAX" - "Копировать запрос")
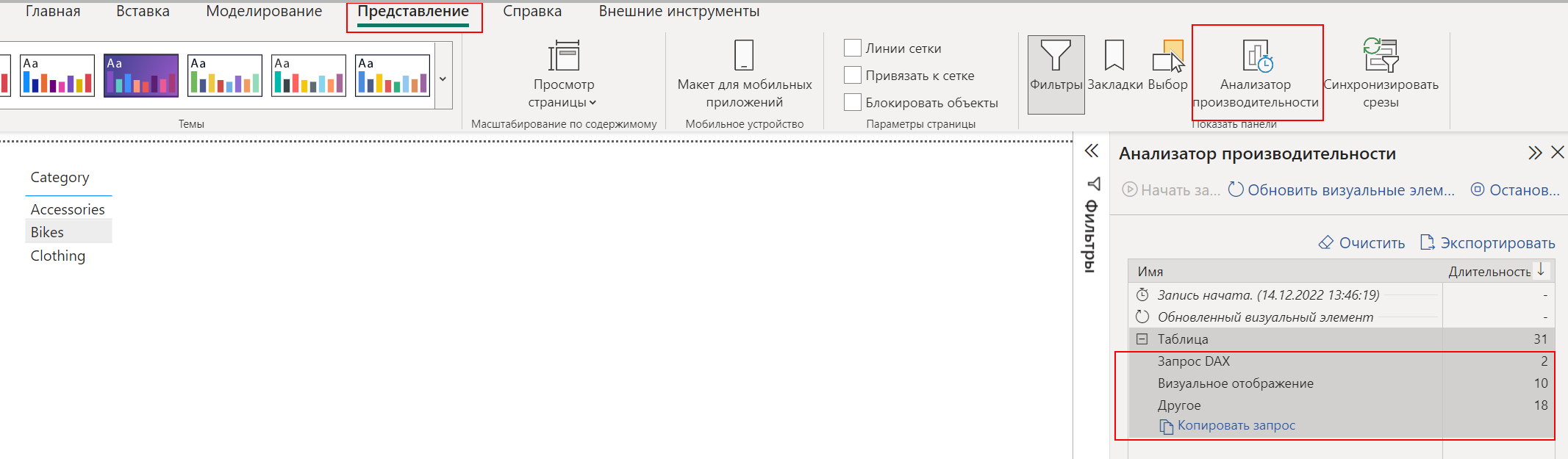
Далее скопируем запрос и вставим его в DAX Studio:

Я убрал лишние строки, где результат запроса ограничивается на 500 строк, т.к. это никак не влияет на результат
Из запроса видно, что для отображения в таблице, с помощью табличной функции DISTINCT формируется таблица категорий товаров на основании столбца Category таблицы Sales. Никаких фильтров у нас нет, поэтому в визуальном элементе отображаются все категории, по которым были продажи.
Но заказчик хочет видеть информацию только по категории Bikes, поэтому добавим в панель фильтров соответствующие условие:
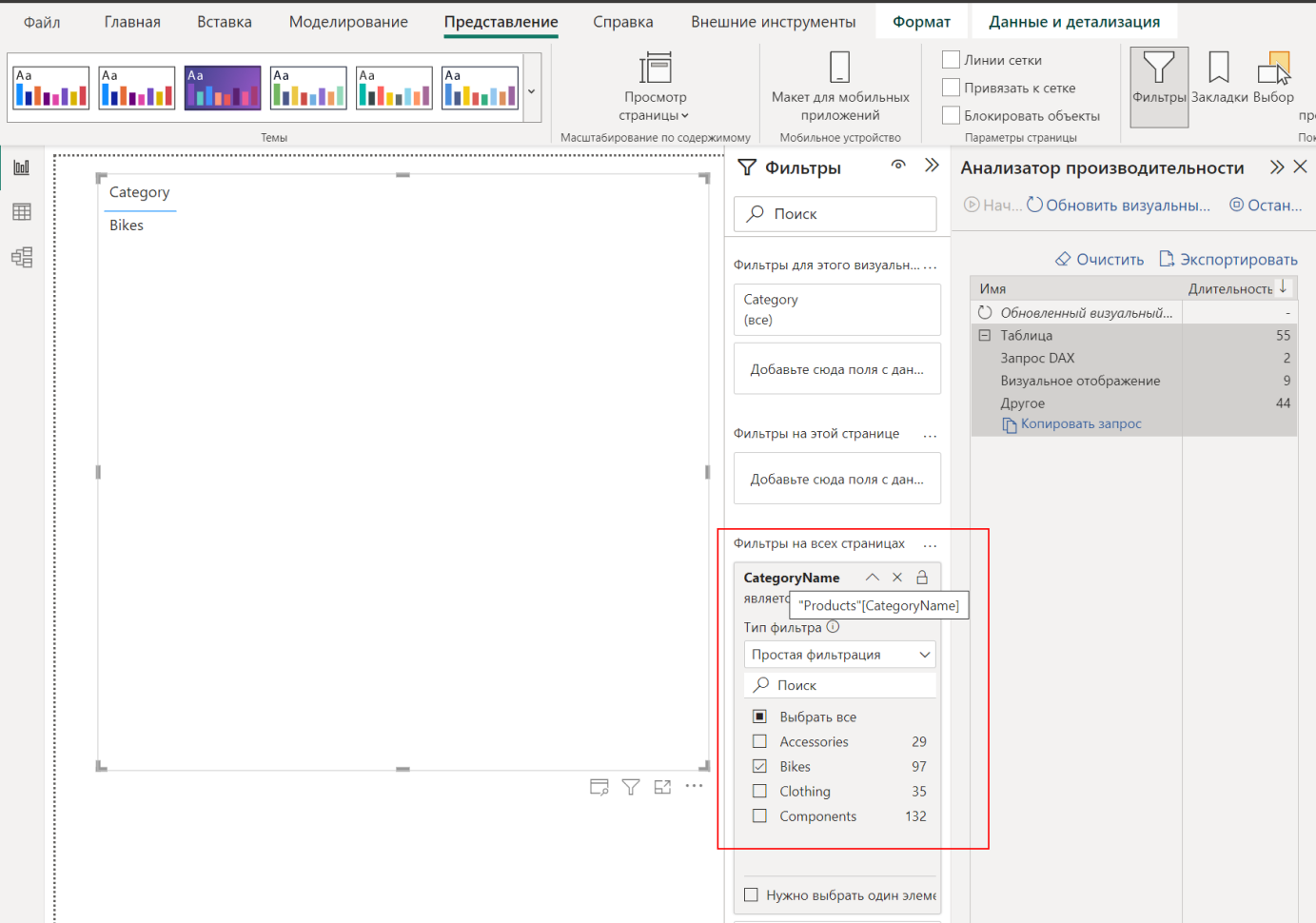
Только вот в фильтр мы добавили столбец CategoryName из таблицы Products, но в визуализации отображается ожидаемый результат в виде одной категории.

Для отображения таблицы по прежнему используется функция DISTINCT, но на этот раз она обернута в функцию CALCULATETABLE, с помощью которой добавляется контекст вычисление с фильтром по таблице Products, который передаётся по связи между таблицами.
А теперь добавим в визуализацию меру:
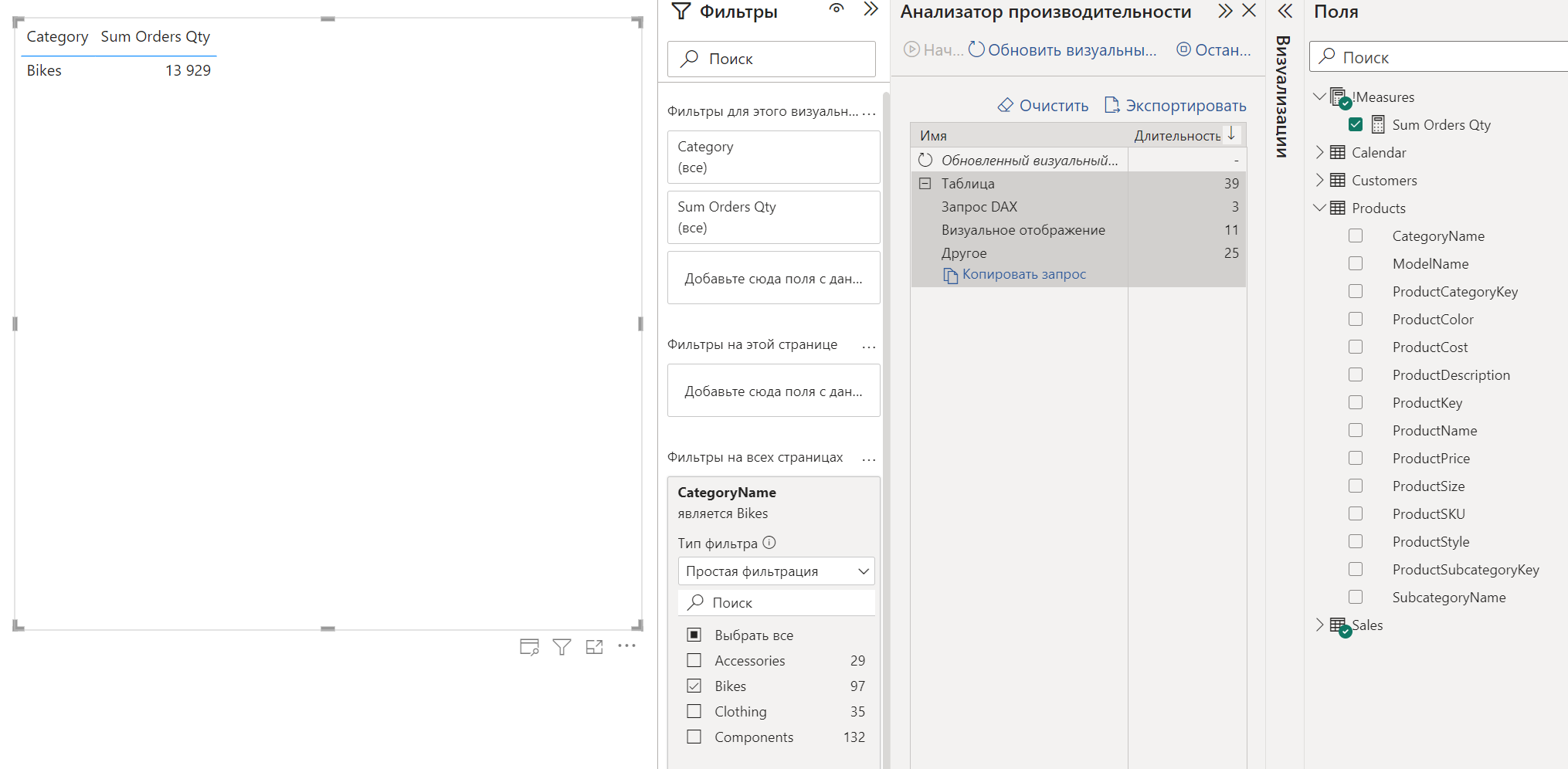
И сразу посмотрим на код запроса:

Результат по прежнему тот, который мы ожидаем - в таблице отображены продажи по одной категории товаров. Но вот функция, которая формирует таблицу для отображения изменилась. Вместо DISTINCT теперь используется функция SUMMARIZECOLUMNS.
Но, прежде чем обратиться к описанию данной функции, создадим новую меру, практически идентичную текущей, за исключением того, что в неё добавлена константа в виде 0:

Такой приём используется довольно часто, чтобы вместо пустоты(BLANK) показывать 0.
Скопируем визуальный элемент и заменим в нём меру, чтобы было удобнее сравнивать:
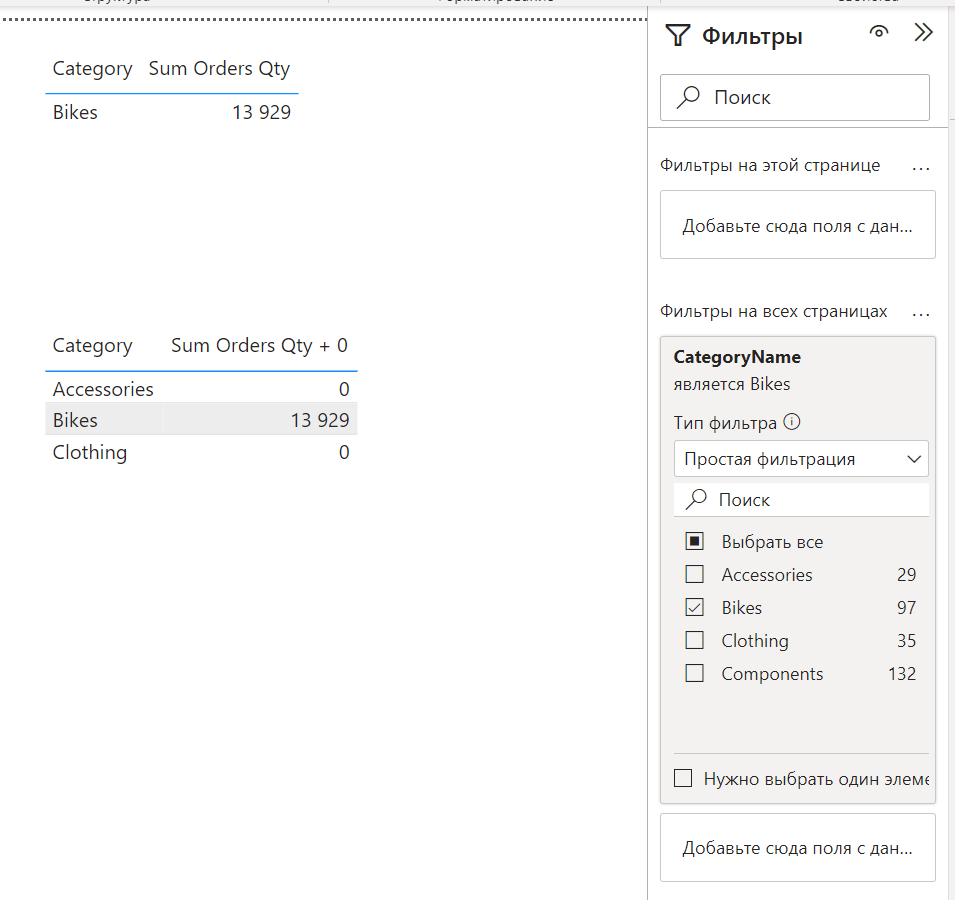
Значение по категории Bikes не изменилось, но появились две категории с нулевым значением, хотя вы по прежнему могли ожидать получить одну категорию, которая выбрана в панели фильтров, ведь таблицы связаны между собой и направление фильтра по связи от Products в Sales. Посмотрим запрос:

Запрос идентичен запросу с изначальной мерой. Почему же там показывается одна категория, а здесь три?
Вот здесь стоит обратиться к теории и описанию функции SUMMARIZECOLUMNS. До примечаний редко кто доходит или внимательно их читает, но здесь кроется вся суть:
Filters in SUMMARIZECOLUMNS only apply to group-by columns from the same table and to measures.
Или по-русски: Фильтры в SUMMARIZECOLUMNS применяются ТОЛЬКО к столбцам группировки из ТОЙ ЖЕ таблицы и К МЕРАМ.
А у нас столбец группировки и столбец фильтра находятся в РАЗНЫХ таблицах, поэтому происходит следующее:
They do not apply to group-by columns from other tables directly, but indirectly through the implied non-empty filter from measures.
То есть, в этом случае к столбцам группировки фильтры из других таблиц применяются не напрямую, а косвенно через подразумеваемый "непустой" фильтр из мер. А в нашей новой мере появилась константа 0, то есть значение, уже вычисленное, на которое никакие фильтры не могут повлиять, поэтому мы как раз и получили "непустое" значение для каждой строки.
Обратите внимание, что так будет работать только сложение и вычитание. Умножение или деление, допустим мы захотим умножить на какой-то коэффициент, по прежнему будут возвращать пустоту:
И в конце немного теории и дополнительное пояснение почему же оно так работает из книги "Подробное руководство по DAX":
Контекст строки осуществляет итерации по таблице, он не фильтрует. Речь идет о построчном сканировании таблицы и последовательном выполнении той или иной операции. Обычно в отчетах нам нужны какие-то агрегации вроде суммы или среднего значения. Во время прохода по таблице контекст строки перебирает строки конкретной таблицы, предоставляя доступ к информации по всем столбцам, но только из этой таблицы. В других таблицах – даже связанных с нашей – контекст строки в этот момент не создан. Иными словами, контекст строки сам по себе автоматически не взаимодействует с существующими в модели связями.
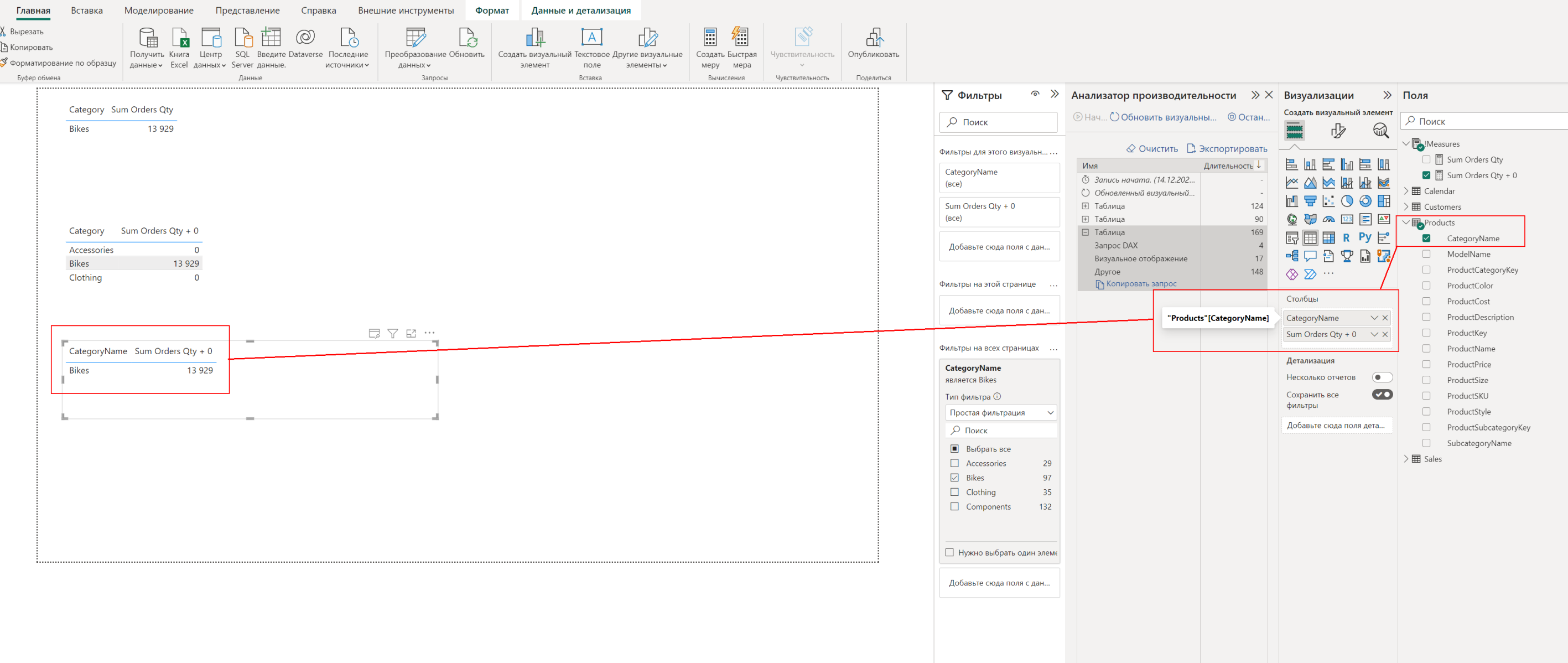
Именно поэтому, если мы хотим получить ожидаемый результат, в нашем визуальном элементе должен находиться столбец из той же таблицы, по которой мы осуществляем фильтрацию или по другому итерацию, просматривая столбец, чтобы выбрать нужные значения:

Ссылка на файл с моделью.